Stop lighting money on fire: Seven tips to improve developer productivity
Software engineering teams are a critical component of many companies, where the effectiveness of these teams can have a significant impact on the company's success.
Making investments in areas such as these in improving developer productivity will pay off significantly, giving development teams more time to focus on delivering business capabilities and less time spent triaging production issues, fighting flaky tests, waiting for unnecessary build steps, or hunting down false production alerts.
Embrace observability
While logs and metrics are a good start for monitoring production systems, those types of monitoring focus on known-knowns. Logs for error scenarios you know about ahead of time, metrics for pre-defined measurements, etc. But what about the unknown-unknowns - where production systems don't behave the way you expect?
Enter observability.
By baking observability into your system, engineers can inspect production behavior in realtime without needing to hurriedly add more logging or metrics in the middle of an incident. The insights offered by observability are valuable in single apps but especially valuable in larger microservice architectures.
The OpenTelemetry project and its various language implementations are a great way to add vendor-agnostic observability into your systems.
Stabilize systems
Time spent dealing with production issues is time not spent adding value to the product. Investments in stability of a product pay off in a big way, in both user satisfaction and productivity of the development team supporting the product. If tackling production stability issues isn't a high priority, the team's bandwidth will be eaten away supporting the product in production.
In addition to the internal stability of the product, investments in making the product resilient against failures of dependent systems in a distributed environment are also key. Otherwise, the team will again lose productivity and focus dealing with the inevitable failures present in any distributed system.
How much manual engineering time does your system require just to keep it running? What would the impact be if that time and focus was instead spent on improving the system?
Tune alerting levels
When development teams have full-lifecycle ownership of their products - that is, they are on-call to support the team's applications in production - alerting at the right time is key to ensure engineers are engaged when production is in trouble.
But over-alerting on-call engineers when there isn't a serious issue has many problems:
- alert fatigue - where too many false-positive alerts cause the on-call engineer to take each alert less seriously - potentially reacting to major issues much slower
- reduced productivity - anyone being repeatedly woken up by false-alarm pages will be less productive during the work day
- less engagement - unnecessarily interrupting engineers on the weekend or waking them up in the middle of the night is a surefire way to reduce their engagement at work
As Charity Majors put it "Closely track how often your team gets alerted. Take ANY out-of-hours-alert seriously, and prioritize the work to fix it. Night time pages are heart attacks"
That is why recently I created tooling to help teams track and visualize how many alerts they are getting - segmented into workday and off-hours alerts. I also created an automated weekly email where team members and engineering leaders can sign up for weekly alert reports sent directly into their inboxes. With approaches like these to raise the visibility of how often engineers are being paged, it's easier for teams to tackle problematic applications and stay on top of alerting issues as their products evolve.
Reduce build times
Time spent waiting for code to compile, tests to run, etc. is not only time that can't be spent doing more valuable activities, it takes developers out of the flow of development work. If a build takes too long, it's very easy to switch over to email, Slack, etc. and lose all the context of what you were working on. To reduce wasted time and context switching, it's key to focus on reducing build time - both at the initial stages of a project and as the project evolves over time.
Tools like the Gradle build cache can save significant time by only executions the build steps required based on the extent of a code change.
For example, this CI build of a significant code change compiled code and executed tests across many Gradle subprojects and took around 12 minutes:

While a smaller change in the same codebase took less than 2 minutes because Gradle pulled the unchanged subproject task results from the cache and only executed the necessary pieces:

There are many Gradle build cache implementations available to choose from, including an S3-compliant backend I wrote (https://github.com/craigatk/object-store-cache-plugin) and use with DigitalOcean Spaces.
Running portions of your build in parallel can also help reduce the overall build time. Trying to parallelize an existing test suite can be a time sink if the tests have any shared state, but setting up a test suite to be able to run in parallel from the beginning is a great investment. Or leveraging the capability of build tools like Gradle to safely run subprojects in parallel can save time even if the tests in an individual subproject can't be safely run in parallel.
Faster debugging of failing tests
Tests are a critical part of a healthy codebase, but debugging failing tests can be a time sink. Especially tests that pass locally but fail in continuous integration (CI) environments.
When running tests locally, it's easier to get the full context of a failure through test output, application logs, and screenshots/videos from mobile or browser tests. Making this same context available when running tests in CI is key to speed up debugging of failing tests that can hold up pull request merges or production deployments.
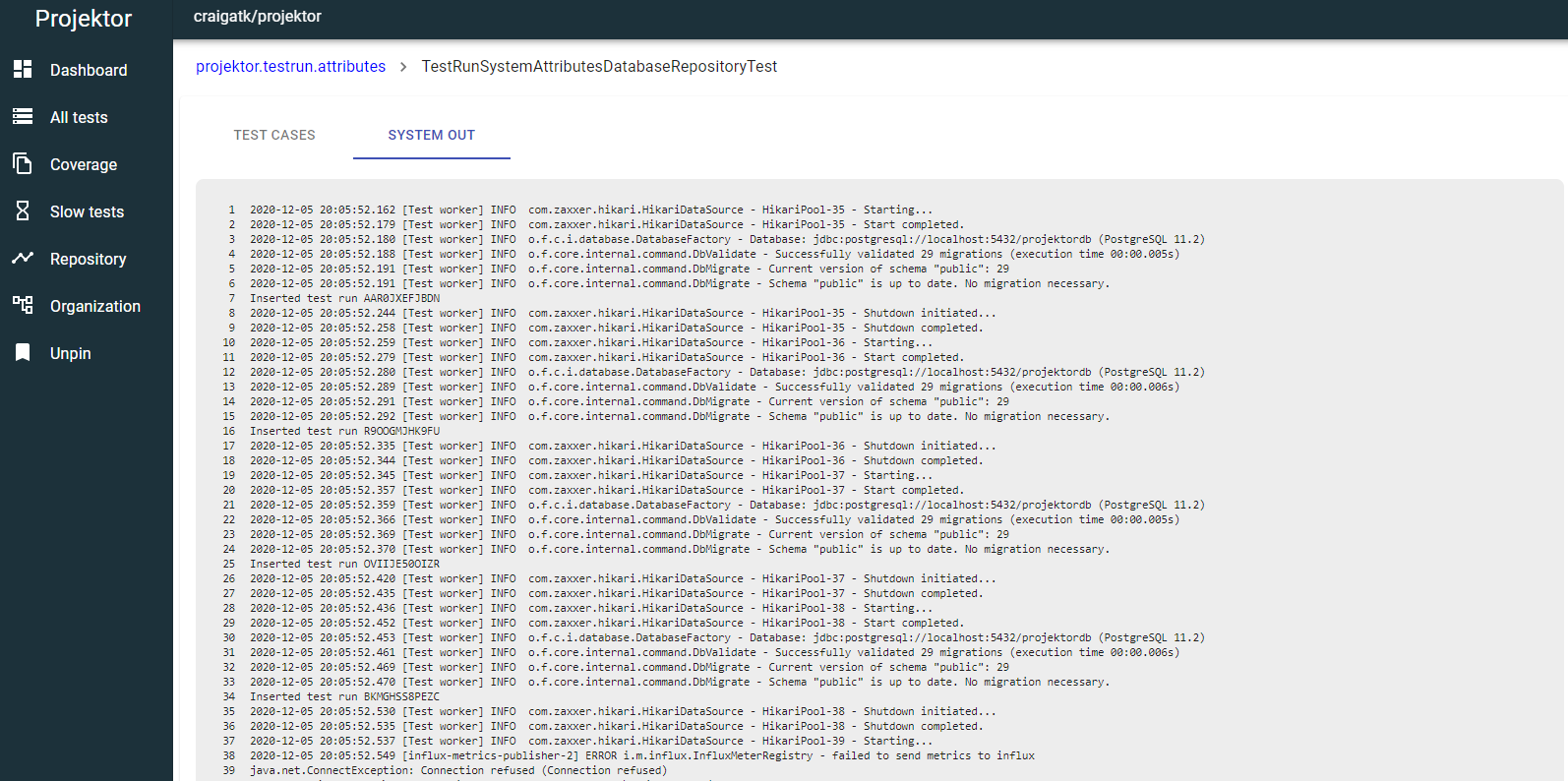
This is why I built features in the Projektor test report tool to give the full log output from each test case:
And displaying screenshots inline with test failures for Cypress browser tests to see what happened when the test failed:
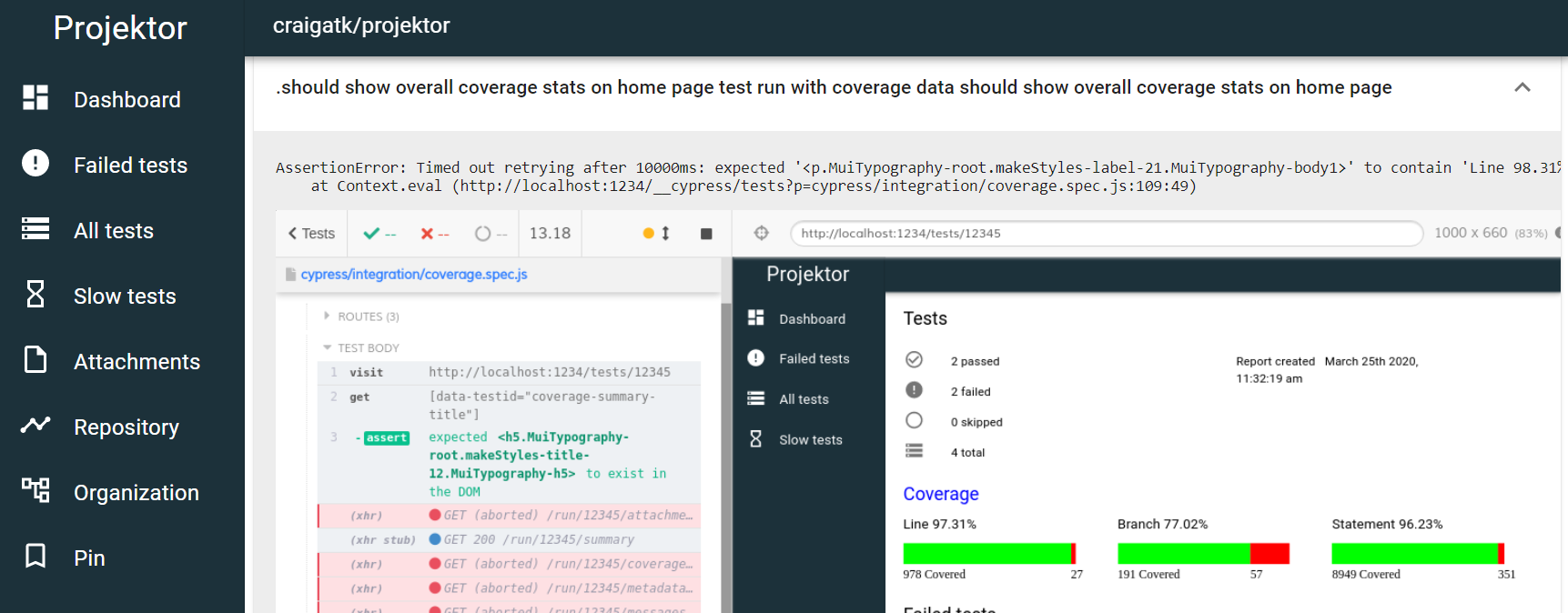
Giving developers as most information and context about test failures in CI reduces the amount of time they're fighting with getting CI green and lets them get back to driving the product forward.
Tackle flaky tests
Flaky tests - that is, tests that fail intermittently - are a pain. These flaky tests cause a variety of issues, including:
- time wasted re-running builds to get flaky tests to pass
- lost trust in the test suite - when a test fails is it identifying a real issue?
Identifying and fixing flaky tests saves the development team time as they no longer have to needlessly re-run builds in the hope of getting a passing build. And the team gets more value out of their investment in writing a test suite as the team trusts their test suite to catch real issues before the code gets into production.
That is why I added flaky test detection into Projektor test reporting tool, to make it easier to identify what tests are flaky and tackle them as soon as possible.
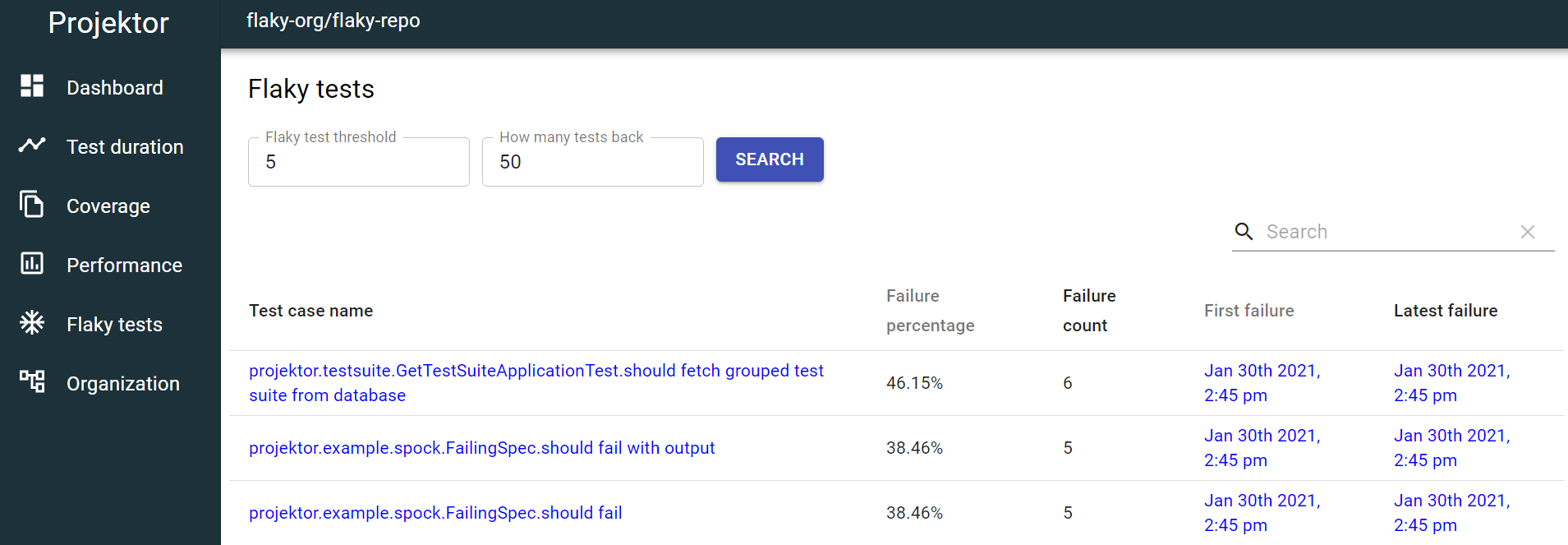
Coincidentally, Projektor's flaky test detection helped me identify some flaky tests in Projektor itself (related to metrics publishing verification). Then I adjusted the testing approach to yield stable tests that still correctly verified that functionality.
Smooth deployment pipelines
Investments in deployment tooling and infrastructure to make deployments automated, repeatable, and stable
reduce the manual time developers spend getting their code to production.
And the smoother it is to deploy to production, the smaller and more frequent the deployments can be -
getting improvements into customers' hands faster while reducing the scope of change that needs investigation
if the deployment introduces issues.
In addition to the deployment of code changes, more seamlessly managing changes to configuration and secrets is also important to reduce the risk of missing or incorrect configuration breaking production.
Conclusion
Invest engineering capacity in these types of improvements for happier, more engaged, and more productive development teams.